This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Indhold leveret af LessWrong. Alt podcastindhold inklusive episoder, grafik og podcastbeskrivelser uploades og leveres direkte af LessWrong eller deres podcastplatformspartner. Hvis du mener, at nogen bruger dit ophavsretligt beskyttede værk uden din tilladelse, kan du følge processen beskrevet her https://da.player.fm/legal.
Minder om LessWrong (Curated & Popular)
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
We help founders make something people want.
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
Catalyst, a Launch by NTT DATA podcast, puts humans at the front and center of digital transformation. Each week, we feature thought leaders who share their insights on reinventing digital experiences, enhancing customer journeys, and driving innovation in the enterprise. From platform transformation to the latest advancements in AI, our guests delve into the challenges and triumphs of digital transformation, emphasizing the critical role of human ingenuity and leadership. Please note that t ...
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
Flash Forward is a show about possible (and not so possible) future scenarios. What would the warranty on a sex robot look like? How would diplomacy work if we couldn’t lie? Could there ever be a fecal transplant black market? (Complicated, it wouldn’t, and yes, respectively, in case you’re curious.) Hosted and produced by award winning science journalist Rose Eveleth, each episode combines audio drama and journalism to go deep on potential tomorrows, and uncovers what those futures might re ...
…
continue reading
Travel, at its best, changes the way we see the world. Join us each week as we dig into stories from people who took a trip—and came home transformed. Travel Tales by AFAR is your ticket to the world, no passport required.
…
continue reading
Custom Manufacturing Industry podcast is an entrepreneurship and motivational podcast on all platforms, hosted by Aaron Clippinger. Being CEO of multiple companies including the signage industry and the software industry, Aaron has over 20 years of consulting and business management. His software has grown internationally and with over a billion dollars annually going through the software. Using his Accounting degree, Aaron will be talking about his organizational ways to get things done. Hi ...
…
continue reading
The Fragmented Podcast is the leading Android developer podcast started by Kaushik Gopal & Donn Felker. Our goal is to help you become a better Android Developer through conversation & to capture the zeitgeist of Android development. We chat about topics such as Testing, Dependency Injection, Patterns and Practices, useful libraries, and much more. We will also be interviewing some of the top developers out there. Subscribe now and join us on the journey of becoming a better Android Developer.
…
continue reading
Player FM - Podcast-app
Gå offline med appen Player FM !
Gå offline med appen Player FM !

))
“o1: A Technical Primer” by Jesse Hoogland
Manage episode 454951409 series 3364760
Indhold leveret af LessWrong. Alt podcastindhold inklusive episoder, grafik og podcastbeskrivelser uploades og leveres direkte af LessWrong eller deres podcastplatformspartner. Hvis du mener, at nogen bruger dit ophavsretligt beskyttede værk uden din tilladelse, kan du følge processen beskrevet her https://da.player.fm/legal.
TL;DR: In September 2024, OpenAI released o1, its first "reasoning model". This model exhibits remarkable test-time scaling laws, which complete a missing piece of the Bitter Lesson and open up a new axis for scaling compute. Following Rush and Ritter (2024) and Brown (2024a, 2024b), I explore four hypotheses for how o1 works and discuss some implications for future scaling and recursive self-improvement.
The Bitter Lesson(s)
The Bitter Lesson is that "general methods that leverage computation are ultimately the most effective, and by a large margin." After a decade of scaling pretraining, it's easy to forget this lesson is not just about learning; it's also about search.
OpenAI didn't forget. Their new "reasoning model" o1 has figured out how to scale search during inference time. This does not use explicit search algorithms. Instead, o1 is trained via RL to get better at implicit search via chain of thought [...]
---
Outline:
(00:40) The Bitter Lesson(s)
(01:56) What we know about o1
(02:09) What OpenAI has told us
(03:26) What OpenAI has showed us
(04:29) Proto-o1: Chain of Thought
(04:41) In-Context Learning
(05:14) Thinking Step-by-Step
(06:02) Majority Vote
(06:47) o1: Four Hypotheses
(08:57) 1. Filter: Guess + Check
(09:50) 2. Evaluation: Process Rewards
(11:29) 3. Guidance: Search / AlphaZero
(13:00) 4. Combination: Learning to Correct
(14:23) Post-o1: (Recursive) Self-Improvement
(16:43) Outlook
---
First published:
December 9th, 2024
Source:
https://www.lesswrong.com/posts/byNYzsfFmb2TpYFPW/o1-a-technical-primer
---
Narrated by TYPE III AUDIO.
---
…
continue reading
The Bitter Lesson(s)
The Bitter Lesson is that "general methods that leverage computation are ultimately the most effective, and by a large margin." After a decade of scaling pretraining, it's easy to forget this lesson is not just about learning; it's also about search.
OpenAI didn't forget. Their new "reasoning model" o1 has figured out how to scale search during inference time. This does not use explicit search algorithms. Instead, o1 is trained via RL to get better at implicit search via chain of thought [...]
---
Outline:
(00:40) The Bitter Lesson(s)
(01:56) What we know about o1
(02:09) What OpenAI has told us
(03:26) What OpenAI has showed us
(04:29) Proto-o1: Chain of Thought
(04:41) In-Context Learning
(05:14) Thinking Step-by-Step
(06:02) Majority Vote
(06:47) o1: Four Hypotheses
(08:57) 1. Filter: Guess + Check
(09:50) 2. Evaluation: Process Rewards
(11:29) 3. Guidance: Search / AlphaZero
(13:00) 4. Combination: Learning to Correct
(14:23) Post-o1: (Recursive) Self-Improvement
(16:43) Outlook
---
First published:
December 9th, 2024
Source:
https://www.lesswrong.com/posts/byNYzsfFmb2TpYFPW/o1-a-technical-primer
---
Narrated by TYPE III AUDIO.
---
Images from the article:

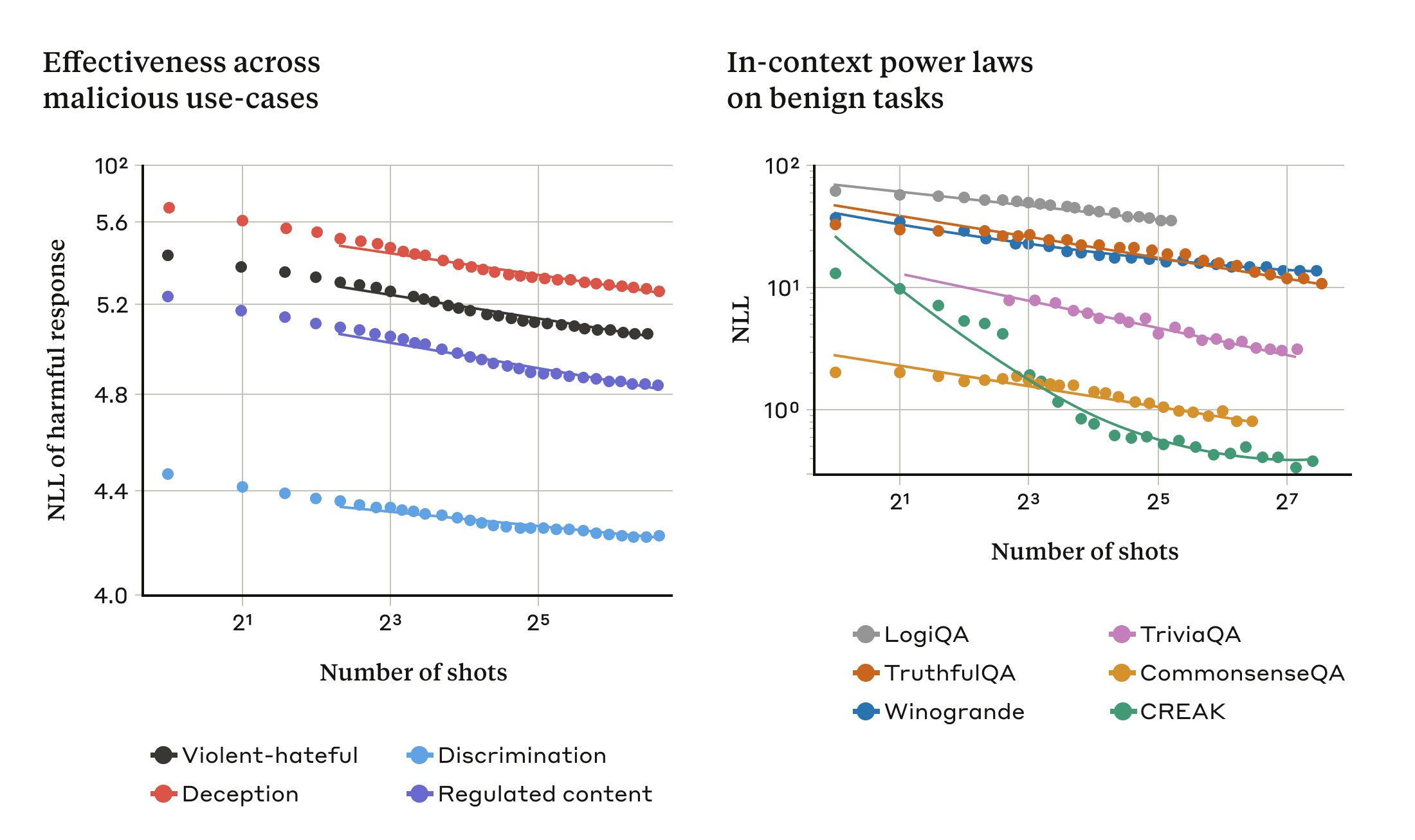 Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.454 episoder
Manage episode 454951409 series 3364760
Indhold leveret af LessWrong. Alt podcastindhold inklusive episoder, grafik og podcastbeskrivelser uploades og leveres direkte af LessWrong eller deres podcastplatformspartner. Hvis du mener, at nogen bruger dit ophavsretligt beskyttede værk uden din tilladelse, kan du følge processen beskrevet her https://da.player.fm/legal.
TL;DR: In September 2024, OpenAI released o1, its first "reasoning model". This model exhibits remarkable test-time scaling laws, which complete a missing piece of the Bitter Lesson and open up a new axis for scaling compute. Following Rush and Ritter (2024) and Brown (2024a, 2024b), I explore four hypotheses for how o1 works and discuss some implications for future scaling and recursive self-improvement.
The Bitter Lesson(s)
The Bitter Lesson is that "general methods that leverage computation are ultimately the most effective, and by a large margin." After a decade of scaling pretraining, it's easy to forget this lesson is not just about learning; it's also about search.
OpenAI didn't forget. Their new "reasoning model" o1 has figured out how to scale search during inference time. This does not use explicit search algorithms. Instead, o1 is trained via RL to get better at implicit search via chain of thought [...]
---
Outline:
(00:40) The Bitter Lesson(s)
(01:56) What we know about o1
(02:09) What OpenAI has told us
(03:26) What OpenAI has showed us
(04:29) Proto-o1: Chain of Thought
(04:41) In-Context Learning
(05:14) Thinking Step-by-Step
(06:02) Majority Vote
(06:47) o1: Four Hypotheses
(08:57) 1. Filter: Guess + Check
(09:50) 2. Evaluation: Process Rewards
(11:29) 3. Guidance: Search / AlphaZero
(13:00) 4. Combination: Learning to Correct
(14:23) Post-o1: (Recursive) Self-Improvement
(16:43) Outlook
---
First published:
December 9th, 2024
Source:
https://www.lesswrong.com/posts/byNYzsfFmb2TpYFPW/o1-a-technical-primer
---
Narrated by TYPE III AUDIO.
---
…
continue reading
The Bitter Lesson(s)
The Bitter Lesson is that "general methods that leverage computation are ultimately the most effective, and by a large margin." After a decade of scaling pretraining, it's easy to forget this lesson is not just about learning; it's also about search.
OpenAI didn't forget. Their new "reasoning model" o1 has figured out how to scale search during inference time. This does not use explicit search algorithms. Instead, o1 is trained via RL to get better at implicit search via chain of thought [...]
---
Outline:
(00:40) The Bitter Lesson(s)
(01:56) What we know about o1
(02:09) What OpenAI has told us
(03:26) What OpenAI has showed us
(04:29) Proto-o1: Chain of Thought
(04:41) In-Context Learning
(05:14) Thinking Step-by-Step
(06:02) Majority Vote
(06:47) o1: Four Hypotheses
(08:57) 1. Filter: Guess + Check
(09:50) 2. Evaluation: Process Rewards
(11:29) 3. Guidance: Search / AlphaZero
(13:00) 4. Combination: Learning to Correct
(14:23) Post-o1: (Recursive) Self-Improvement
(16:43) Outlook
---
First published:
December 9th, 2024
Source:
https://www.lesswrong.com/posts/byNYzsfFmb2TpYFPW/o1-a-technical-primer
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.454 episoder
Alle episoder
×Velkommen til Player FM!
Player FM is scanning the web for high-quality podcasts for you to enjoy right now. It's the best podcast app and works on Android, iPhone, and the web. Signup to sync subscriptions across devices.
Minder om LessWrong (Curated & Popular)
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
We help founders make something people want.
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
Catalyst, a Launch by NTT DATA podcast, puts humans at the front and center of digital transformation. Each week, we feature thought leaders who share their insights on reinventing digital experiences, enhancing customer journeys, and driving innovation in the enterprise. From platform transformation to the latest advancements in AI, our guests delve into the challenges and triumphs of digital transformation, emphasizing the critical role of human ingenuity and leadership. Please note that t ...
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
Flash Forward is a show about possible (and not so possible) future scenarios. What would the warranty on a sex robot look like? How would diplomacy work if we couldn’t lie? Could there ever be a fecal transplant black market? (Complicated, it wouldn’t, and yes, respectively, in case you’re curious.) Hosted and produced by award winning science journalist Rose Eveleth, each episode combines audio drama and journalism to go deep on potential tomorrows, and uncovers what those futures might re ...
…
continue reading
Travel, at its best, changes the way we see the world. Join us each week as we dig into stories from people who took a trip—and came home transformed. Travel Tales by AFAR is your ticket to the world, no passport required.
…
continue reading
Custom Manufacturing Industry podcast is an entrepreneurship and motivational podcast on all platforms, hosted by Aaron Clippinger. Being CEO of multiple companies including the signage industry and the software industry, Aaron has over 20 years of consulting and business management. His software has grown internationally and with over a billion dollars annually going through the software. Using his Accounting degree, Aaron will be talking about his organizational ways to get things done. Hi ...
…
continue reading
The Fragmented Podcast is the leading Android developer podcast started by Kaushik Gopal & Donn Felker. Our goal is to help you become a better Android Developer through conversation & to capture the zeitgeist of Android development. We chat about topics such as Testing, Dependency Injection, Patterns and Practices, useful libraries, and much more. We will also be interviewing some of the top developers out there. Subscribe now and join us on the journey of becoming a better Android Developer.
…
continue reading
Player FM - Podcast-app
Gå offline med appen Player FM !
Gå offline med appen Player FM !



